
The demo always works.
You feed Whisper a clean Hindi sample from Common Voice, get a near-perfect transcript, ship the prototype, sleep well. Then the first real production file lands — a phone call from a Marathi-speaking customer, a Hindi-English standup recording, a WhatsApp voice note recorded inside a moving auto — and the same model produces transcripts that read like a drunk autocomplete.
Welcome to building STT for India.
This isn’t a Whisper-specific problem. Every open-source STT model we’ve put into production fails on real Indian audio in roughly the same way. Switching from Whisper to IndicWav2Vec, jumping to a bigger Whisper variant, or fine-tuning Wav2Vec2 almost never closes the gap — because the gap isn’t really a model problem.
In English, Whisper Genuinely Is the Champion
Let’s give credit where it’s due. For clean English audio — podcasts, lectures, dictation, even moderate-noise calls — Whisper large-v3 is excellent. Open weights, runs anywhere, decent latency on a GPU, transcripts good enough to hand straight to a downstream LLM with almost no cleanup.
That’s the reputation it earned. And that reputation is the trap.
Because the moment you cross into Indian-language territory — and especially the moment your audio source stops being a quiet room — the same model behaves like a completely different system.
What “Indian Audio” Actually Sounds Like in Production
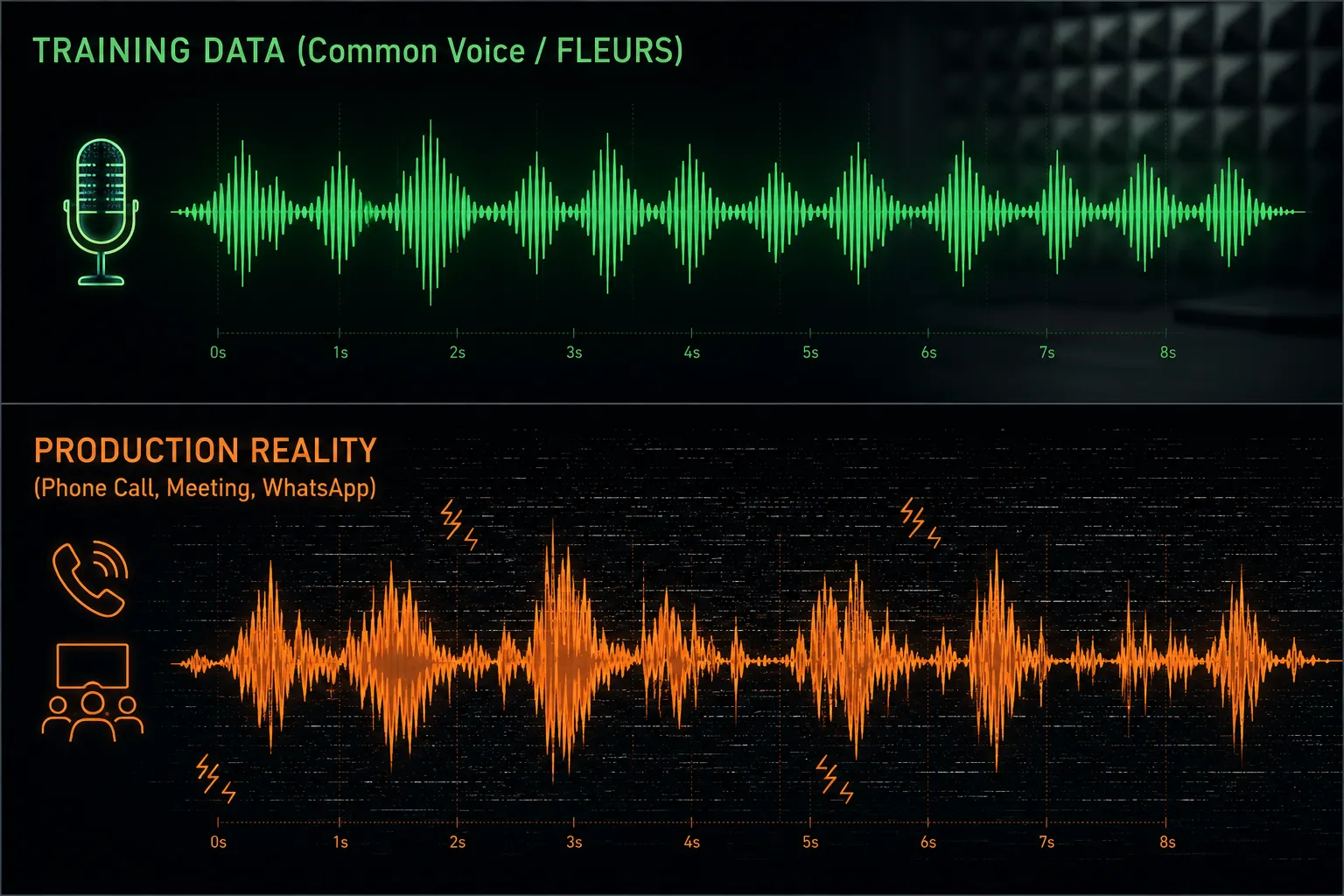
This is the part most STT benchmarks skip entirely. They evaluate models on Common Voice or FLEURS — datasets recorded by volunteers reading prepared sentences carefully into a decent microphone in a quiet room.
That is not what production Indian audio looks like. Production audio is:
- Phone calls at 8kHz, with mobile-network compression artifacts that destroy high frequencies before the audio ever reaches you.
- Conference calls with multiple speakers, room echo, AC hum, and the laptop fan two inches from the mic.
- WhatsApp voice notes recorded on the move — traffic in the background, the speaker turning their head, the phone bumping against fabric.
- Code-switching sentences like “Sir woh wala invoice ka payment kab process hoga, can you check once?” — Hindi grammar carrying English nouns, switching mid-clause.
- Regional accents stacked on top — a Marathi speaker’s Hindi sounds different from a Bengali speaker’s Hindi sounds different from a Tamil speaker’s English, and your model has to handle all of them.
- Filler patterns that barely exist in Western training data — “yaar,” “matlab,” “actually-actually,” “haan haan haan” in rapid succession.
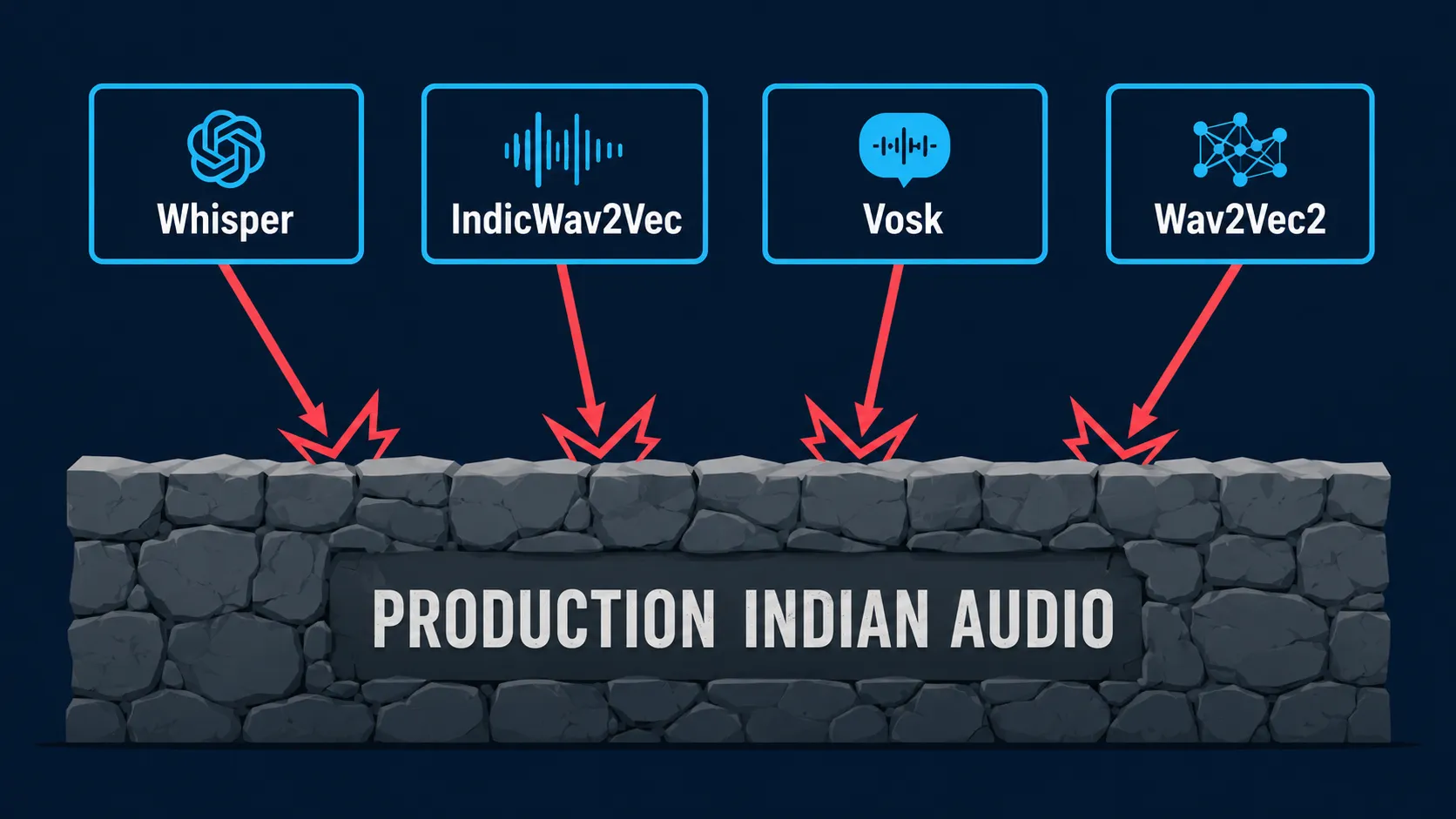
Whisper has barely seen any of this. IndicWav2Vec has seen a little more, but still mostly clean studio data. Vosk and base Wav2Vec2? Even less. None of them were trained on the audio you actually have.
Why Whisper Falls Apart Here
Three concrete failure modes, in roughly the order you’ll hit them:
1. Sampling rate and bandwidth. Whisper is trained on 16kHz audio. Phone calls arrive at 8kHz. Upsampling to 16kHz doesn’t add back the high-frequency information the telephony codec already threw away — it just gives Whisper an input that looks right while being acoustically lobotomized. Consonants like ‘s,’ ‘sh,’ and ‘ch’ live in those higher bands; without them, “shaakahari” comes out as “saakari,” and the model confidently moves on.
2. Acoustic mismatch. Whisper’s training set is dominated by clean web audio in a handful of well-resourced languages. Hindi is in there, but the kind of Hindi audio it saw is podcast Hindi, news-anchor Hindi, audiobook Hindi — not call-center Hindi spoken at 1.5× that pace, by someone whose first language is Gujarati, over a 3G connection while they’re walking.
3. Code-switching collapse. Whisper detects language at the utterance level, which is a clean enough idea for English-only or Hindi-only audio. The moment a sentence starts in Hindi, switches to English for three nouns, and ends in Hindi, you get one of two failures — the whole utterance forced into one language (with the other transcribed as phonetic nonsense), or unpredictable mid-sentence flips. We’ve watched Whisper render an English noun inside a Hindi sentence as a Hindi-sounding phrase that almost makes grammatical sense and is completely wrong. That kind of almost right output is more dangerous than a clean error, because nothing downstream flags it — your action-item extractor, your keyword tagger, your sentiment classifier all process it as if it were correct.
The Other Open-Source Options Don’t Save You
The natural next move is: “okay, Whisper is general-purpose, let me try something India-specific.” This usually lands in one of three places.
ai4bharat IndicWav2Vec / IndicConformer. The most India-aware open-source family out there, by a wide margin. The team has done real, sustained work building Indic-language datasets that no one else has bothered to assemble. On clean read-speech in Hindi, Bengali, Tamil, or Marathi, you will get noticeably better results than vanilla Whisper. But the moment the audio is conversational, noisy, or code-switched — the same failure modes return. The training data still wasn’t production call audio.
Vosk. Lightweight, runs on CPU, has Indic language packs. The right tool if you need offline STT on a low-resource device for a fixed vocabulary in clean conditions — kiosks, embedded systems, narrow command grammars. For open-domain Indian conversational audio, it isn’t close.
Wav2Vec2 base + fine-tuning. In theory, you fine-tune on your own data and the problem dissolves. In practice, fine-tuning Wav2Vec2 well requires hundreds of hours of cleanly-labeled audio in your domain, your dialect, and your recording conditions. If you have that dataset, you don’t need this blog post. If you don’t, you’ll burn three weeks producing a model that’s measurably worse than the Whisper output you started with.
The pattern is the same across all three: every open-source model is trained on data that looks almost nothing like what arrives at your endpoint. Swapping one for another doesn’t fix it, because architecture isn’t the bottleneck — training data is.
What Actually Works in Production
After enough of this, we landed on a two-step approach for Indian-language audio in production at Webs Optimization. Neither step is exotic. Both are non-negotiable.
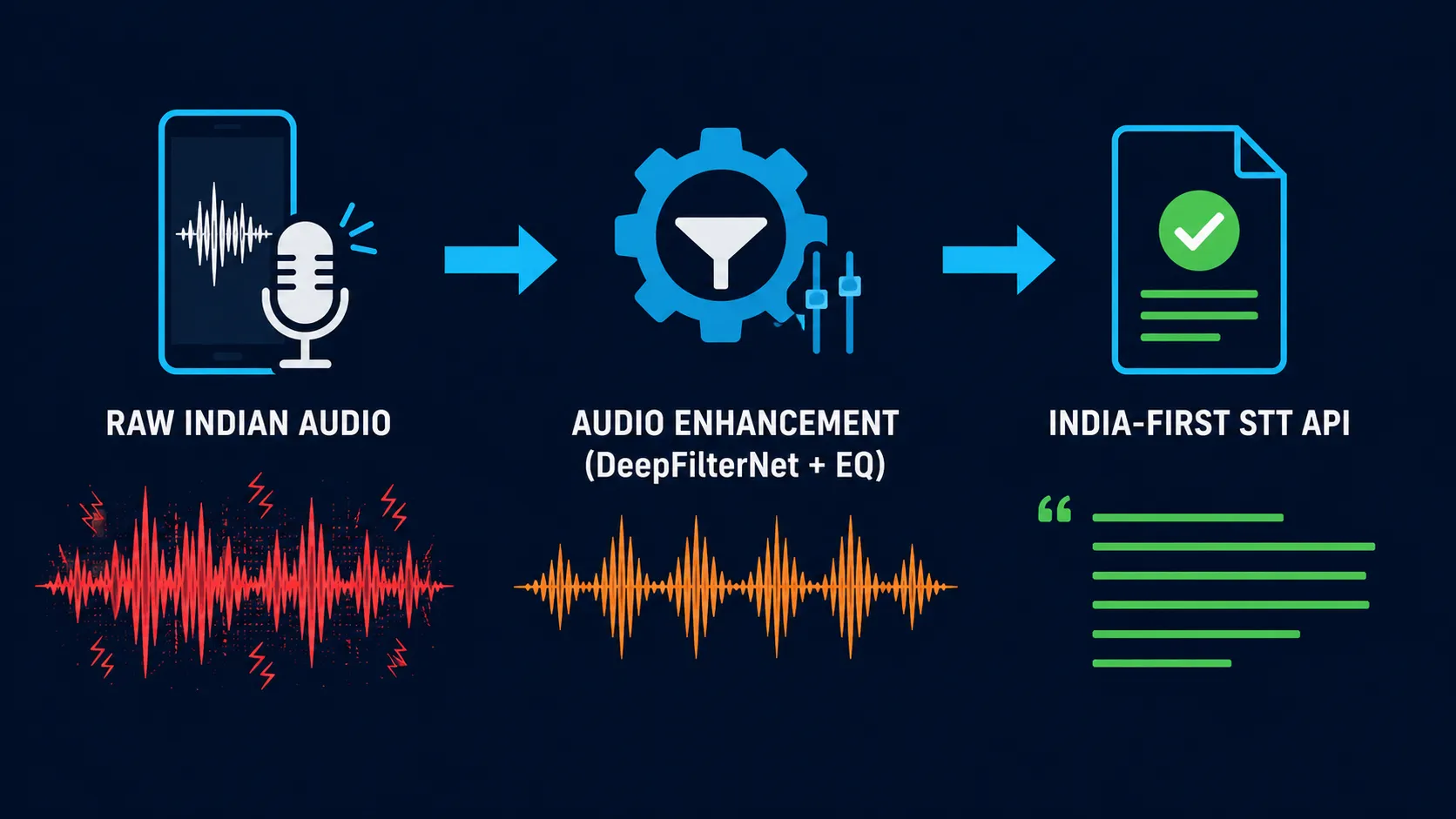
Step 1 — Clean the audio before STT, not after.
The single biggest accuracy lift we’ve ever seen on Indian production audio came from running every file through an audio enhancement pipeline before it touches an STT model. DeepFilterNet for AI-based speech denoising, EQ shaping for the human vocal range, dynamic-range compression to even out volumes, normalization at the end. The full pipeline — including the actual Python code — is in Cleaning the Signal: Our 6-Step Audio Enhancement Pipeline using DeepFilterNet & FFmpeg.
“Garbage in, garbage out” is more true for Indian audio than for English, not less. Because the gap between your audio and the model’s training distribution is larger, every dB of noise you remove counts for more.
Step 2 — For the STT itself, stop reaching for open-source.
This is the conclusion most teams resist for cost reasons and then arrive at anyway after a quarter of debugging Whisper outputs. For Hindi and Indian regional languages, the India-first commercial providers have done the data work that no open-source release has: they’ve collected real call-center audio, real code-switched audio, real regional-accent audio, and trained on it.
We benchmarked eight of them on real Indian production audio across six scenarios. The full breakdown — accuracy, cost per hour, regional language coverage, which one to pick for which use case — is in We Tested 8 STT APIs for Indian Languages So You Don’t Have To.
The short version: ₹10–₹45 per hour, transcripts that don’t require a downstream LLM to guess what was actually said.
The Bottom Line
Whisper is an extraordinary piece of work. IndicWav2Vec is too, in a narrower way. Neither of them — and none of their open-source siblings — is enough on its own to build a serious Indian-language STT product on in 2026.
The real production pattern looks like this: clean your audio aggressively before STT, then pay for an India-first commercial API that has actually been trained on the kind of audio you’re throwing at it. The combined cost is small. The cost of not doing this is months of debugging hallucinated transcripts, broken keyword extraction, and unhappy users wondering why your “AI” can’t understand a sentence their grandmother would have no trouble with.
Open source caught up to commercial STT on clean English audio around 2023. For Indian languages in real production conditions, that day hasn’t arrived yet. Build accordingly.