Processing audio is uniquely hostile to web servers. A text request takes milliseconds. A video upload takes seconds. But processing a 1-hour audio file—denoising, transcribing, diarizing—can take minutes.
If you try to do this in a standard HTTP request loop, your server will hang. Your load balancer will time out (usually after 30-60s). And your users will rage quit.
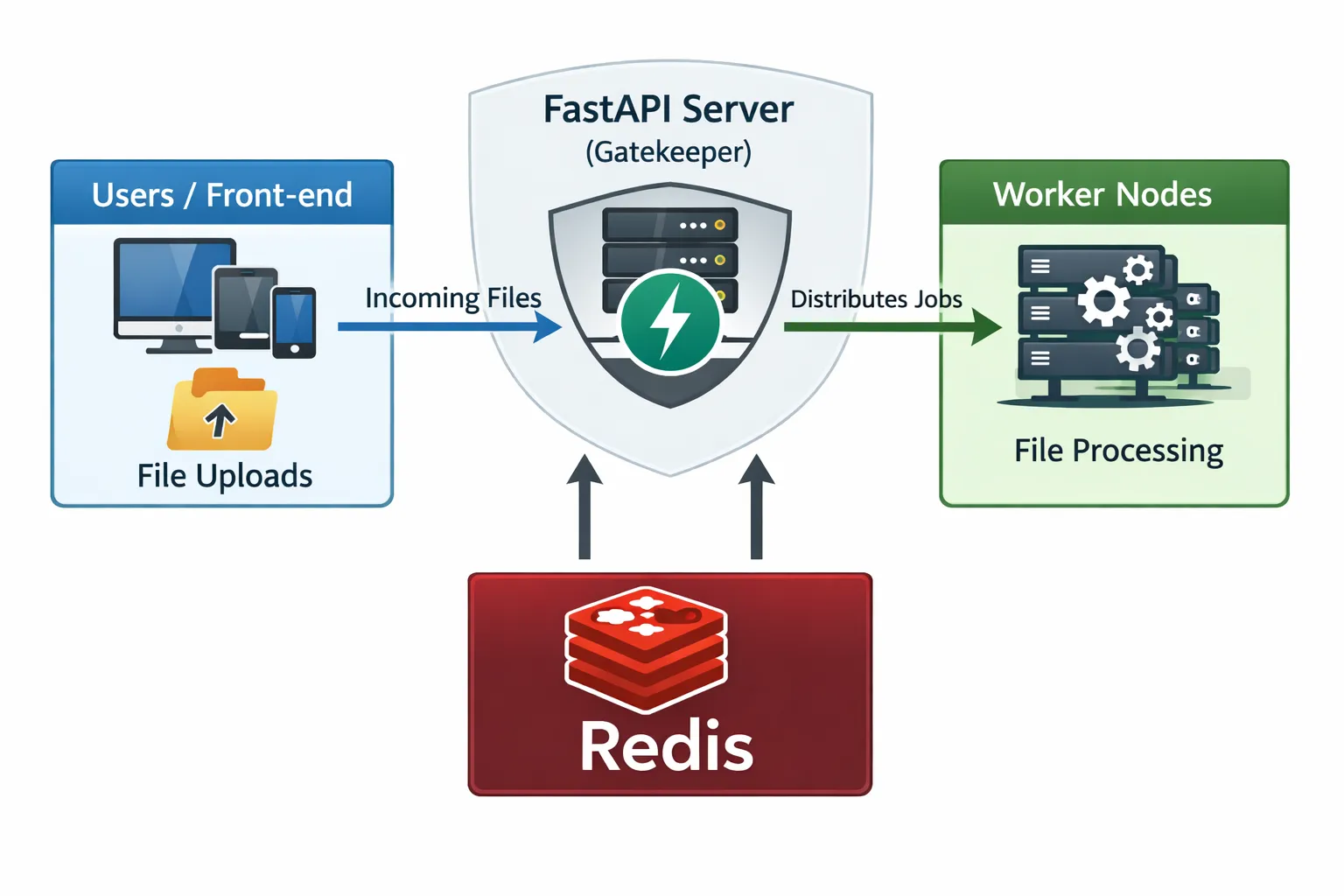
Here is how we architected our platform to handle high-volume audio ingestion using FastAPI, Celery, and Redis to separate the “Ingestion Layer” from the “Processing Layer.”
The Infrastructure: Gatekeeper vs. Workhorse
We adhere to a strict philosophy: The API layer should never do math. Its only job is to validate input, store the file, and acknowledge receipt.
- Ingestion Layer (FastAPI): Optimization goal is Throughput. It needs to accept 1,000 files/sec without blinking.
- Processing Layer (Celery Workers): Optimization goal is Completion. It churns through the queue at its own sustainable pace.
The Ingestion Endpoint
Our endpoint is designed to fail fast if the input is bad, but return fast if the input is good. We use FastAPI’s BackgroundTasks or Celery’s apply_async to offload the work.

@router.post("/api/upload-audio")
async def ingest_audio_endpoint(
audio_file: UploadFile = File(...),
):
if not is_valid_audio_format(audio_file.filename):
return ErrorResponse("Invalid format. Please upload MP3 or WAV.")
job_uuid = generate_unique_id()
safe_path = f"/storage/uploads/{job_uuid}_{audio_file.filename}"
with open(safe_path, "wb") as disk_buffer:
shutil.copyfileobj(audio_file.file, disk_buffer)
db.create_job_record(id=job_uuid, status="QUEUED")
process_audio_pipeline.apply_async(
args=[job_uuid, safe_path],
task_id=job_uuid
)
return SuccessResponse(job_id=job_uuid, status="QUEUED")The Worker and “Backpressure”
Redis acts as a buffer. If 10,000 users upload files simultaneously, the API accepts them all. Redis holds them. The workers process them 5 at a time (or however many cores we have). This prevents the servers from crashing under load—the queue just gets longer, but the system stays up.
We also implement a Chunking Strategy for long files (“The Elephant Problem”). If a file is > 30 minutes, it’s too big for efficient RAM usage and single-request API limits. We slice it.

@celery_app.task(bind=True, queue="heavy_audio_tasks")
def process_audio_pipeline(self, job_id, file_path):
try:
duration = get_audio_duration(file_path)
if duration > 1800: # 30 mins
logger.info(f"Large file detected ({duration}s). Engaging Chunking Strategy.")
chunks = split_audio_into_chunks(file_path, chunk_size=600)
full_transcript = []
for chunk in chunks:
text = transcribe_audio(chunk)
full_transcript.append(text)
else:
full_transcript = transcribe_audio(file_path)
clean_audio = run_noise_reduction(file_path)
db.update_job(job_id, status="COMPLETED", result=full_transcript)
except Exception as e:
logger.error(f"Job {job_id} crashed: {e}")
db.update_job(job_id, status="FAILED", error=str(e))Resilience: The “Dead Letter Queue”
Network blips happen. APIs go down. If our transcription provider returns a 503 error, we don’t want to fail the job immediately.
We configured Celery with Automatic Retries. We use exponential backoff (wait 10s, then 20s, then 40s) to give the external service time to recover.
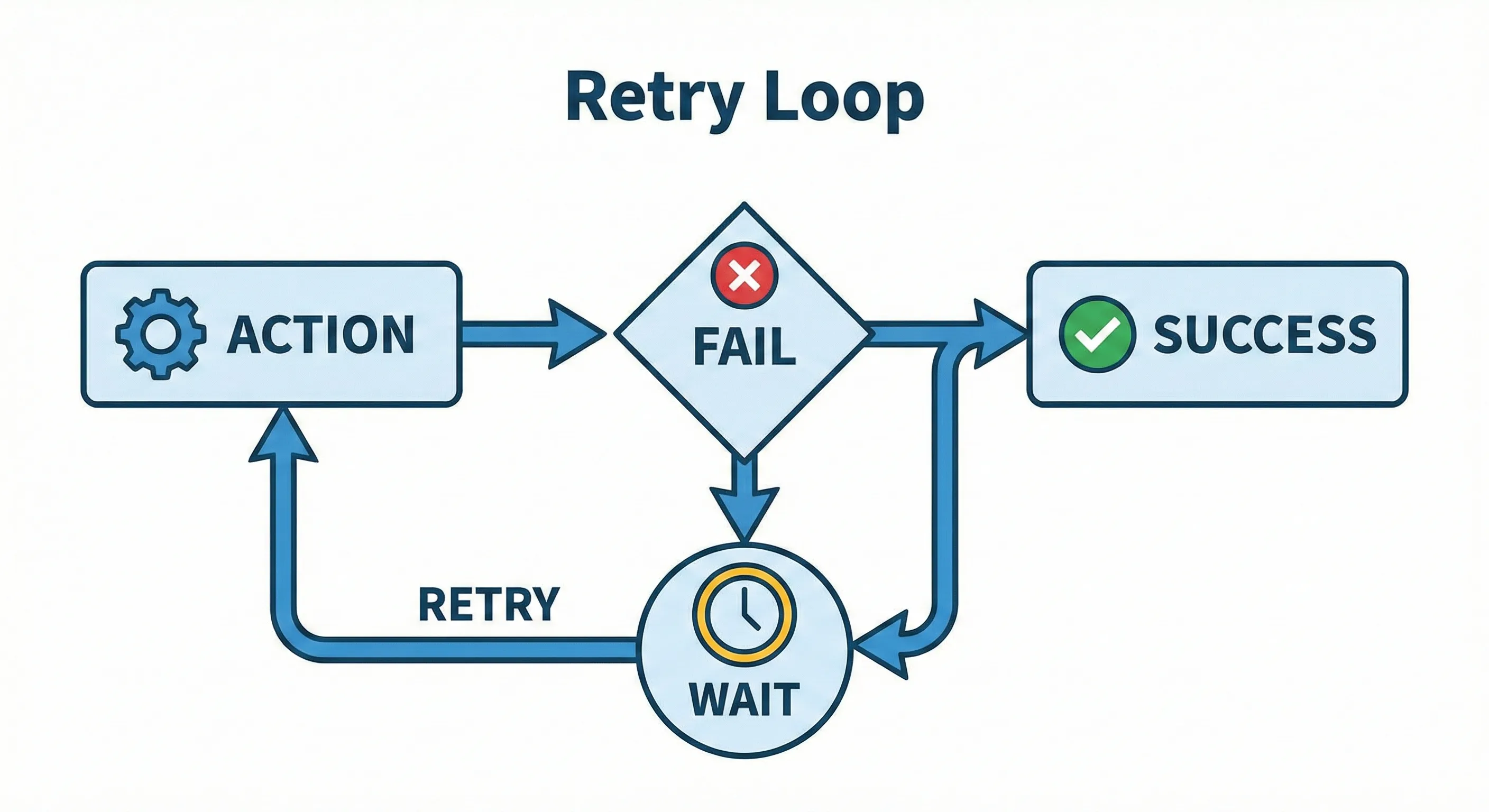
@celery_app.task(bind=True, max_retries=3, default_retry_delay=30)
def process_audio_pipeline(self, job_id, ...):
try:
call_external_api()
except NetworkError as exc:
self.retry(exc=exc)By decoupling the Ingestion from the Processing, we built a system that can absorb a spike of 1,000 concurrent uploads without breaking a sweat. The uploads finish instantly, and the workers churn through the queue at a steady, stable pace.