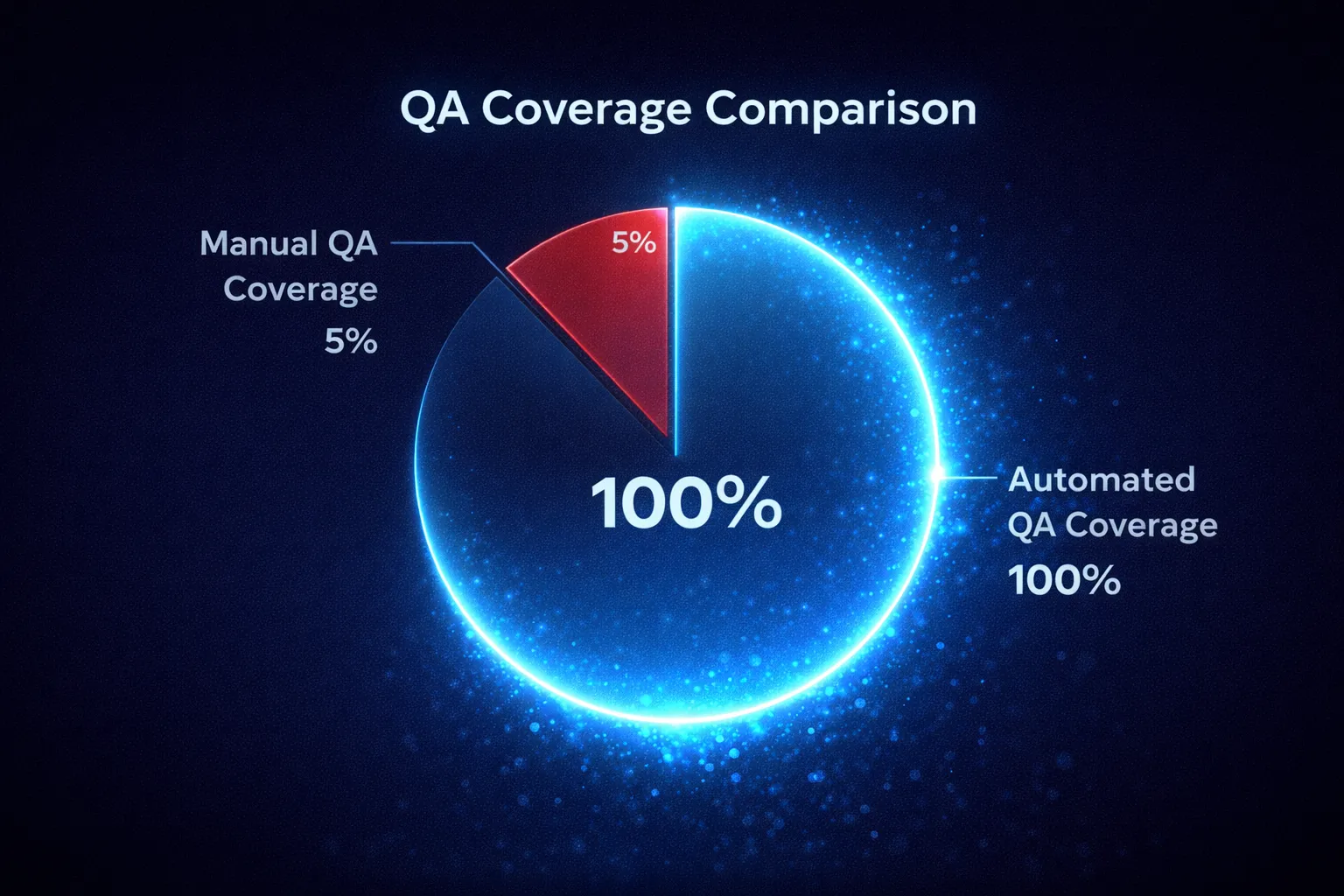
The industry standard for Quality Assurance (QA) in call centers hasn’t changed in 20 years. Large teams of human QA managers listen to recorded calls, fill out a scorecard, and grade the agent.
The problem? They can only listen to about 2-5% of calls.
That means 95% of your customer interactions—the good, the bad, and the disastrous—happens in the dark. Mis-selling, compliance violations, and rude behavior go unnoticed until a customer complains or a lawsuit is filed.
The 100% Coverage Model
Our automated transcription and analysis platform flips this model on its head. Instead of sampling, we analyze 100% of calls.
How It Works
We don’t just transcribe text; we extract structured intelligence. Our “Agent Scoring” engine provides a granular breakdown of every single interaction.

result = {
"agent_score": 8.5,
"good_behavior": [
"Clearly explained the refund policy",
"Used a professional tone even when customer was angry",
"Verified customer identity correctly"
],
"areas_for_improvement": [
"Did not upsell the premium package",
"Interrupted the customer twice during the complaint"
],
"executive_summary": "Strong performance on conflict resolution, but missed revenue opportunity."
}Eliminating Human Bias: The “Calibration” Problem
One of the biggest headaches in manual QA is Calibration.
- Manager A is “The Nice Guy” and gives everyone 9/10.
- Manager B is “The Stickler” and gives everyone 6/10.
This makes it impossible to compare agents fairly. An agent on Manager B’s team looks terrible on paper compared to Manager A’s team, even if they are performing better.
Our system uses standardized “Scoring Parameters” stored in our database. Whether it’s Monday morning or Friday afternoon, the scoring criteria remain exactly the same. The AI doesn’t get tired, it doesn’t hold grudges, and it doesn’t have “bad days.”
def generate_agent_scorecard(conversation_text, grading_rubric):
"""
Apply a consistent grading rubric to a conversation using LLM inference.
"""
rubric_str = json.dumps(grading_rubric)
prompt = f"""
You are an impartial QA Evaluator.
Here is the Grading Rubric you must follow strictly:
{rubric_str}
Analyze the following transcribed conversation:
{conversation_text}
Return a detailed scorecard with citations.
"""
scorecard = call_llm_inference(prompt)
return scorecardThe Power of Trend Analysis
When you monitor 100% of calls, you unlock Macro Trends. Manual QA can tell you “Bob had a bad call on Tuesday.” Automated QA can tell you “The entire sales team has stopped asking for referrals since the script change last week.”
The Business Impact
- Risk Mitigation: You catch the one “fatal” compliance error in 1,000 calls that a human would have missed.
- Training Data: You can identify trends. “Why is the whole team failing at the ‘Closing’ phase this week?”
- Cost: An AI checking 100% of calls often costs less than a human team checking 5%.
We aren’t replacing QA teams; we are giving them superpowers. Instead of hunting for needles in a haystack, they are presented with a dashboard of “Needs Attention” calls, allowing them to focus on coaching rather than listening to dead air.