
Silence is golden—except when you are paying for it.
Most transcription APIs, including Deepgram and OpenAI’s Whisper, bill by the second. If you send a 10-minute audio file where the customer was on hold for 3 minutes, you are paying to transcribe 3 minutes of dead air.
At scale—processing thousands of hours a month—this “Silence Tax” adds up to thousands of dollars in wasted operational spend.
The “Silence Tax” Solution
We built a smart pre-processing layer that intelligently removes non-essential silence before the file is ever sent to the transcription provider.
The Algorithm
Using an audio processing library (like pydub), we scan the audio for segments that drop below a certain decibel threshold (e.g., -40dB) for a sustained period (e.g., > 3 seconds).
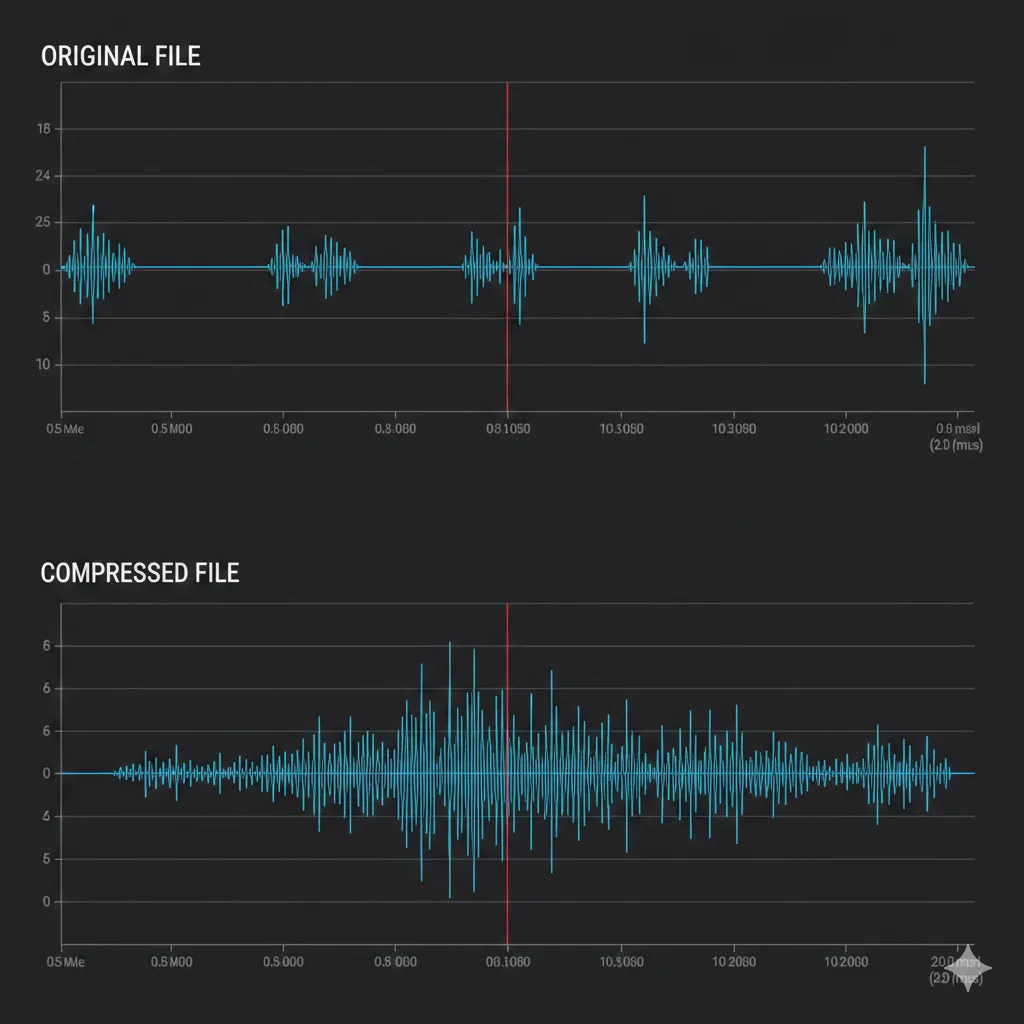
The Risk: Edge Clipping A naive approach (just cutting everything under -40dB) is dangerous. You risk cutting off the first millisecond of a word (“_ello” instead of “Hello”), making the transcript inaccurate. Our solution? Safety Buffers. We keep 500ms of “silence” on either side of the cut. This ensures the audio decays naturally and “breathes,” preventing the robotic implementation that ruins lesser tools.
def trim_silence_smartly(input_file, silence_threshold=-40, min_silence_len=3000):
"""
Removes long periods of silence from an audio file to save costs.
"""
audio = AudioSegment.from_file(input_file)
chunks = split_on_silence(
audio,
min_silence_len=MIN_SILENCE_DURATION,
silence_thresh=SILENCE_DB_THRESHOLD,
keep_silence=SAFETY_BUFFER_MS # CRITICAL: Keep buffer so words aren't clipped
)
if not chunks:
return None
compressed_audio = chunks[0]
for chunk in chunks[1:]:
compressed_audio += chunk
original_sec = len(audio) / 1000
new_sec = len(compressed_audio) / 1000
saved_percent = (1 - (new_sec / original_sec)) * 100
print(f"Compressed {original_sec}s -> {new_sec}s. Savings: {saved_percent}%")
return compressed_audioThe math of Savings
We track exactly how much silence we remove for every job.
cost_per_minute = 0.0043 # Standard API pricing
monthly_volume_minutes = 100000
raw_cost = monthly_volume_minutes * cost_per_minute
optimized_cost = (monthly_volume_minutes * 0.82) * cost_per_minute # 18% reduction
print(f"Monthly Savings: ${raw_cost - optimized_cost}")Real-World Impact
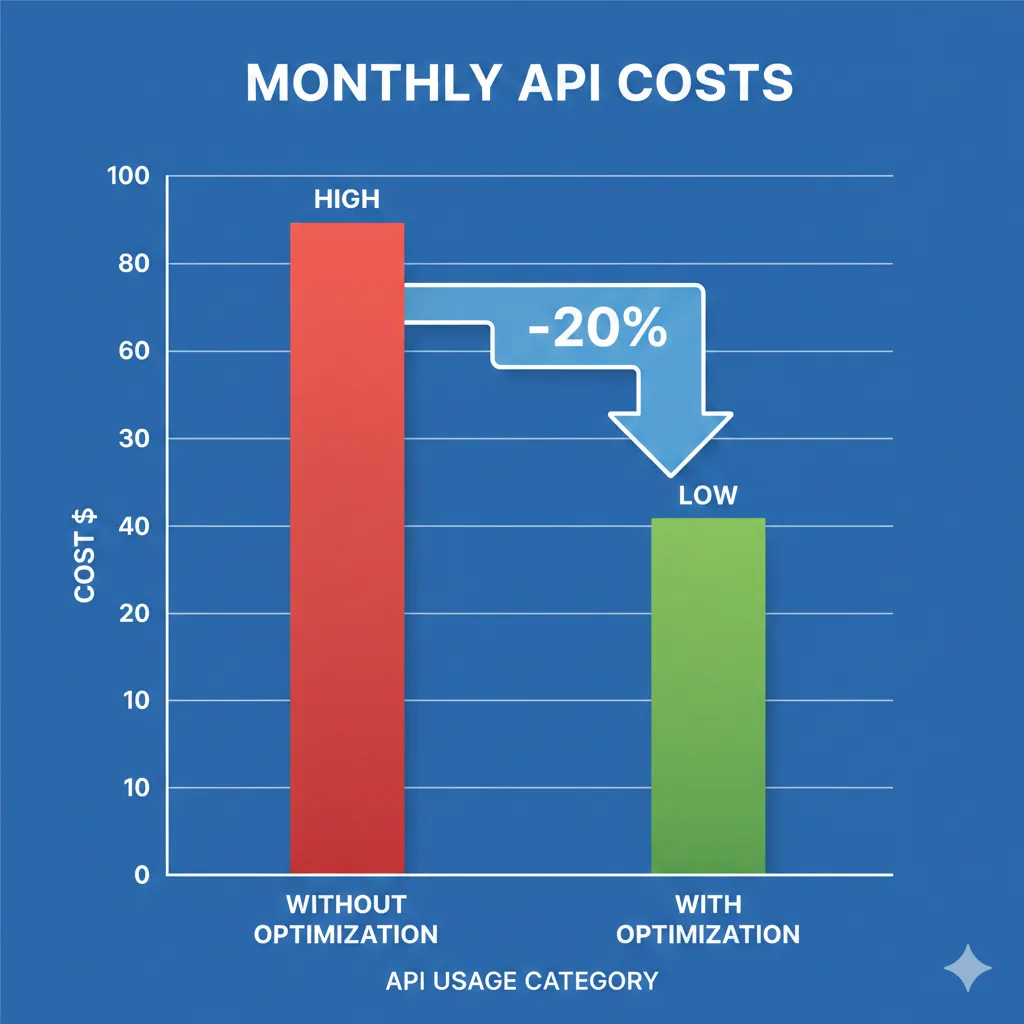
On average, a typical customer service call contains 15-20% silence (hold times, pauses while looking up data, connection delays).
| Metric | Without Optimization | With Optimization |
|---|---|---|
| Avg File Duration | 10 min | 8.2 min |
| API Cost (per million mins) | $4,300 | $3,526 |
| Monthly Savings | $0 | $774 |
By stripping this out:
- Direct Cost Reduction: Our API bill dropped by ~18%.
- Faster Processing: Shorter files mean lower latency. We return results to the user faster.
- Cleaner Transcripts: AI models sometimes “hallucinate” text when trying to interpret long periods of static (e.g., outputting “Thank you” repeatedly in silence). Removing silence stops this ghost text.
Innovation isn’t always about adding features. Sometimes, it’s about removing what you don’t need.